[java] 멀티 프로세스와 멀티 스레드, 스레드풀
프로세스와 스레드
이번 포스팅에서는 프로세스와 스레드, 그리고 멀티 프로세스와 멀티 스레드의 차이를 알아보고 추가로 spring 에서 스레드 풀이 어떻게 관리되는지도 함께 알아보겠습니다. 프로세스와 스레드는 개론적인 이야기가 되겠습니다.
프로세스
프로세스는 컴퓨터를 사용하는 사람이라면 익숙하게 접해봤을 개념입니다. 우리가 크롬, intellij 와 같은 프로그램을 실행하면 어떻게 될까요? 프로그램은 보조기억장치에 저장되어 있지만 실행하는 순간 프로그램이 메모리에 적재되면서 프로세스가 생성됩니다. 이 때 커널 영역에는 PCB 가, 사용자 영역에는 스택 영역, 힙 영역, 데이터 영역, 코드 영역이 올라갑니다.
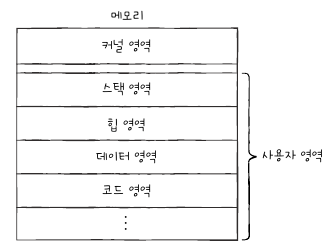
PCB(Process Control Block)는 멀티 프로세스를 위한 태그로, 나중에 얘기할 문맥 교환(context switching) 을 위한 정보입니다. PCB 에는 PID, 레지스터값, 프로세스 상태, CPU 스케줄링 정보, 메모리 정보 등을 가지고 있습니다. 멀티 프로세스에서 더 자세히 설명하겠습니다.
사용자 영역에는 실행 명령어인 코드 영역, Static 변수 혹은 Global 변수를 저장하는 데이터 영역, 동적 메모리 영역인 힙 영역, 지역 변수, 매개변수, 반환 값 등을 저장하는 스택 영역으로 구분됩니다. 이중 코드 영역과 데이터 영역은 크기가 변하지 않기 때문에 정적 할당 영역이고, 힙 영역과 스택 영역은 프로세스 실행 과정에서 크기가 변할 수 있기 때문에 동적 할당 영역입니다.
스레드
컴퓨터를 구매할 때 cpu 스펙에서 8코어 16 스레드와 같은 단어를 접해본 경험이 있을겁니다. 이 스레드는 CPU 안에서 ‘명령어를 실행하는 단위’로, 스레드가 코어에 2개 이상이면 멀티스레드 프로세서로, 여러 개의 명령어를 동시에 실행할 수 있습니다.
하지만 여기서 말하고자 하는 스레드는 조금 다른데요. cpu 관련 용어를 하드웨어 스레드라고 한다면 지금부터 말할 스레드는 소프트웨어 스레드로, 이 글에서는 “스레드” 라고 부르겠습니다. 스레드는 프로세스를 구성하는 실행의 단위입니다. 스레드는 프로세스의 자원을 이용하여 프로그램을 동작시키는데요. 스레드는 실행에 필요한 최소한의 정보(프로그램 카운터를 포함한 레지스터, 스택 영역) 만을 유지한 채 프로세스 자원을 공유합니다. PCB 의 나머지 정보나 힙, 데이터, 코드 영역은 다른 스레드와 공유하는거죠.
프로세스와 스레드
여기까지 봤을 때 프로세스와 스레드는 같으면서도 다른 것처럼 느껴집니다. 사실 프로세스와 스레드를 확실하게 나누기는 힘듭니다. 프로세스와 스레드는 별개의 개념이 아니라 둘 다 “실행의 문맥” 이며 처리방식의 일종입니다. 실제로 리눅스에서는 프로세스와 스레드를 크게 구분 짓지 않습니다. 물론 엄밀히 하자면 프로세스는 운영체제로부터 자원을 할당받은 작업의 단위이며 스레드는 프로세스가 할당받은 자원을 이용하는 실행 흐름의 단위 라고도 할 수 있습니다.
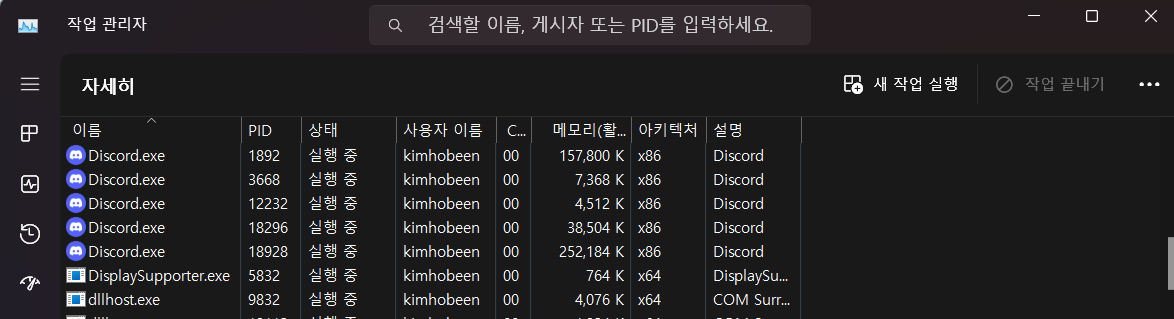
그렇다고 프로그램 1개 = 프로세스 1개로 생각하면 안됩니다. 예를 들어 디스코드를 실행한다고 해도, 디스코드 내에서 자식 프로세스가 계속 만들어질 수 있기 때문입니다. 아래와 같이 말이죠. 자세한 내용은 멀티 프로세스에서 확인해보겠습니다.
참고
리눅스에는 프로세스와 스레드를 동일하게 봅니다.
- 리눅스에서는 사용자 스레드 당 커널 스레드 하나가 매칭이 됩니다. 그래서 리눅스 커널 입장에서는 각각의 스레드가 하나의 프로세스로 실행됩니다. 하지만 여기서 프로세스는 메모리를 공유하기 때문에 light weight process 로 구분됩니다.
- 리눅스에는 PID (process id), TGID(thread group id), TID(thread id) 가 있는데 사용자 입장에서는 PID 로 보이고 커널 입장에서는 TID 로 보입니다. 따라서 스레드별로 PID 는 같아서 같은 프로세스로 보이지만 커널 입장에서는 다 다른 TID를 가지고 있습니다.
멀티 프로세스와 멀티 스레드
멀티 프로세스
멀티 프로세스를 얘기하기 전, 동시성(Concurrency) 와 병렬성(Parallelism) 에 대해 간단하게 짚고 가겠습니다. 동시성이란 아이러니하게도 동시에 실행되는 ‘것처럼’ 구현하는 것입니다. 예를 들어서 싱글 코어 환경에서 크롬과 인텔리제이를 켰다고 생각해보겠습니다. 코어는 1개이기 때문에 한번에 실행할 수 있는 프로세스는 1개이지만 CPU 는 두 프로세스를 끊임없이 반복해서 실행하면서 마치 동시에 실행되고 있는 것처럼 만듭니다. 이는 한 프로세스에서 멀티 스레드를 구현할 때도 같습니다. 반면, 병렬성은 정말로 두 프로세스를 동시에 실행하는 것입니다. 멀티 코어 환경이나 멀티스레드 환경에서 가능하며 물리적으로 진짜 동시에 처리하는 것입니다.
하지만 두 경우 모두 프로세스를 반복해서 CPU 에 적재하고 바꾸는 과정이 계속됩니다. 이러한 과정 속에서 프로세스가 동시에 실행되는 것이 멀티 프로세스입니다. 멀티 프로세스에서 중요한 내용은 문맥 교환(context switching) 인데요. 보통 컨텍스트 스위칭이라고 많이 부릅니다. A, B 프로세스가 실행되고 있다고 할 때 문맥 교환은 다음과 같은 개략적인 과정으로 실행됩니다.
- 프로세스 A 실행 중
- 프로세스 A 의 문맥을 PCB 에 저장 (PID, 레지스터값, 프로세스 상태, CPU 스케줄링 정보, 메모리 정보 등)
- 프로세스 B 의 PCB 로부터 문맥 가져오기
- 프로세스 B 실행
- 프로세스 B 의 문맥을 PCB 에 저장 (PID, 레지스터값, 프로세스 상태, CPU 스케줄링 정보, 메모리 정보 등)
- 프로세스 A 의 PCB 로부터 문맥 가져오기
- 프로세스 A 실행 …
위와 같은 과정을 거치며 A -> B -> A 순서대로 프로세스가 반복됩니다. 이 반복되는 과정이 빠르기 때문에 우리는 동시에 실행되는 것처럼 느낍니다. 여기서 컨텍스트 스위칭은 2, 3번이나 5, 6번처럼 PCB 에 현재까지 한 작업을 저장하고 다른 프로세스의 PCB 를 적재하는 과정입니다. 컨텍스트 스위칭을 하는 이유는, 프로세스를 변경하기 전에 작업을 어디까지 했는지 PCB 에 저장해줘야 다음에 다시 실행할 때 그 지점부터 이어서 할 수 있기 때문입니다.
이는 프로세스 내에서 프로세스가 계층적 구조를 가질 때도 마찬가지입니다. 위 디스코드 사진에서 보듯 부모 디스코드 프로세스가 필요한 기능(음성 채널, DM) 을 자식 프로세스로 실행하여 멀티 프로세스로 관리할 수 있습니다. 이러한 멀티 프로세스가 실행될 때도 컨텍스트 스위칭의 과정을 거치면서 동시성을 가지고 반복적으로 실행됩니다. 이때 자식프로세스는 부모와 별개의 메모리 영역을 확보해야 합니다.
멀티 스레드
멀티 스레드는 기본적으로 한 프로세스 내에서 자원을 공유하는 여러 스레드가 실행되는 것입니다. 구체적으로는 스레드 ID, 프로그램 카운터 값, 레지스터 값, 스택 영역을 제외하고 모든 자원을 공유하게 됩니다.
멀티 프로세스가 컨텍스트 스위칭을 한다고 해서 멀티 스레드가 해당 과정을 거치지 않는 것은 아닙니다. 스레드별로 레지스터값과 프로그램 카운터값이 다르니 CPU 는 새로운 연산을 해야 합니다. 따라서 스레드 컨텍스트 스위칭이 발생합니다. 물론 다른 메모리 영역이나 PCB 값은 동일하니 프로세스보다는 컨텍스트 스위칭 비용이 적어지기는 합니다.
멀티 프로세스 vs 멀티 스레드
| 멀티 프로세스 | 멀티 스레드 | |
|---|---|---|
| 장점 | 독립된 구조로 안정성이 높음 동기화 작업이 필요하지 않음 |
공유된 자원으로 통신비용 절감, 효율적인 메모리 사용 컨텍스트 스위칭 비용이 적음 협업에 유리 |
| 단점 | 멀티 스레드보다 많은 메모리와 CPU 차지 컨텍스트 스위칭에 더 많은 비용 발생 |
공유 자원을 관리해야 하고 동기화 문제 발생(병목현상, 데드락) 하나의 스레드에 문제가 발생하면 전체 프로세스에 영향 주의깊은 설계가 필요, 디버깅이 어려움 불필요한 부분까지 동기화하면 대기시간으로 성능 저하 |
| 기타 | IPC 를 사용하여 프로세스 간 통신 가능 |
스레드 풀
웹 어플리케이션에서 작 요청이 오면 어플리케이션은 스레드를 통해 해당 요청을 수행하게 됩니다. 요청 1개 당 1개의 스레드가 할당되는거죠. 이 때, 요청이 올 때마다 스레드를 생성한다면 어떻게 될까요? 다음과 같은 문제가 발생합니다.
첫번째는 Thread 생성비용이 크기 때문에 요청에 대한 응답 시간 증가한다는 것입니다. 자바는 스레드 생성 시 One-to-One 스레드 모델(Ref 4 참고)로, 커널 스레드가 반드시 생성됩니다. 커널 스레드는 생성 및 관리가 어렵기 때문에 생성 비용이 많이 들고, 이에 따라 응답 시간이 증가하게 됩니다.
두번째는 Thread 수가 계속 증가할 수 있다 점입니다. Thread 가 계속 늘어나면 메모리를 더 차지하고 컨텍스트 스위칭이 더 자주 발생해 CPU 오버헤드 문제가 생길 수도 있습니다.
Thread Pool(스레드 풀)
이러한 문제를 해결하기 위해 나온 게 Thread Pool 입니다. 스레드 풀이란 스레드를 허용된 개수 안에서 사용하도록 제한하는 시스템입니다. 스레드 풀은 아래와 같이 동작합니다.
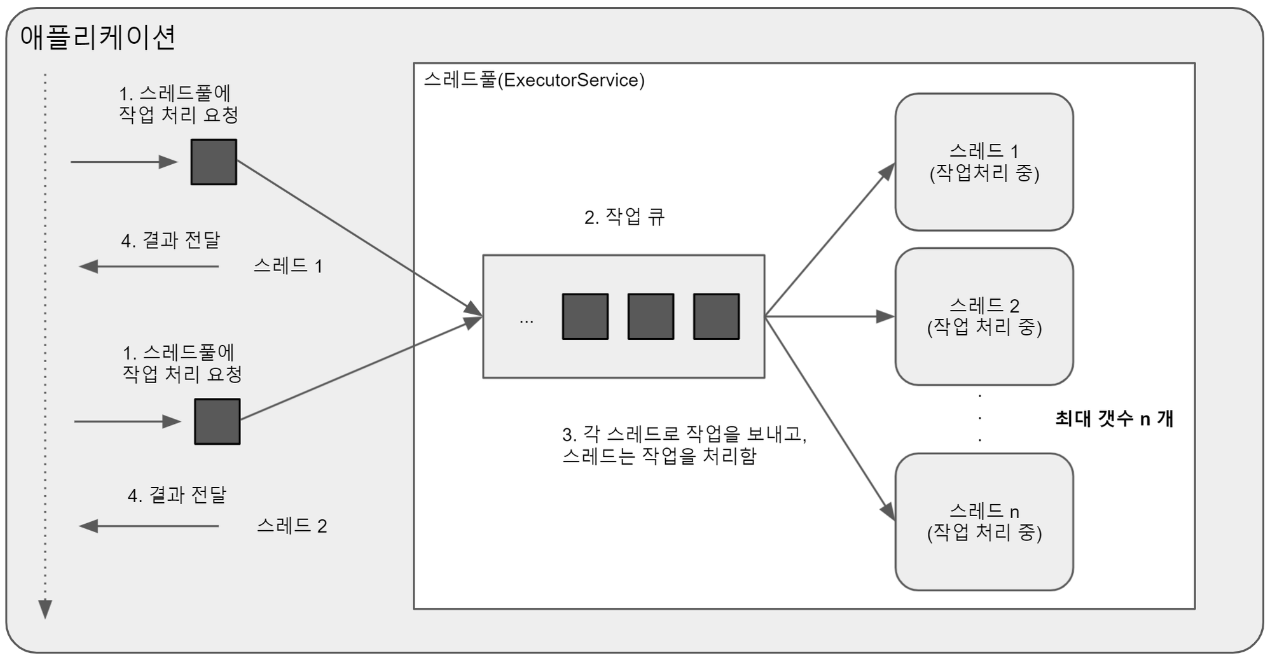
스레드 풀에 작업처리 요청이 들어오면 작업 큐에 쌓이게 되고 각 스레드는 작업 큐에서 작업을 빼내 처리합니다. 정해진 양 만큼의 스레드를 사용하고, 한번 사용한 스레드는 없어지지 않습니다. 따라서 생성 비용을 줄이고, CPU 오버헤드를 방지합니다.
ThreadPoolExecutor
자바는 ThreadPoolExecutor 라는 클래스를 통해 스레드 풀을 제공합니다. 해당 클래스는 Executors 클래스의 메서드로 만들 수 있는데, newCachedThreadPool() 메서드는 1개 이상의 스레드가 추가되었을 경우 60초 동안 스레드가 아무 작업하지 않으면 해당 스레드를 풀에서 쫓아내고, newFixedThreadPool(int nThreads) 메서드는 스레드가 놀고 있어도 제재를 가하지 않습니다. 자세한 동작은 Ref 5 를 참고해주세요.
Tomcat
스레드 풀에서 톰캣 얘기를 뺄 수 없겠죠. Tomcat 은 스프링 부트의 내장 서블릿 컨테이너로, JAVA 의 ThreadPoolExecutor 과 매우 유사한 자체 스레드 풀 구현체를 가지고 있습니다. 그리고 몇 가지 알아야 할 개념도 있습니다.
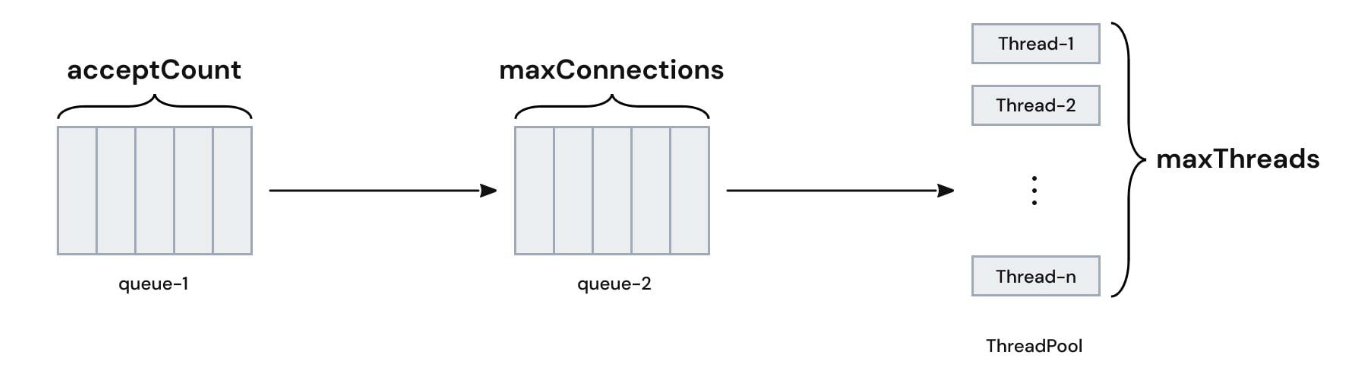
Max-Connections
서버가 허용하고 처리할 수 있는 최대 연결 개수입니다. 웹에서 요청이 들어오면 Tomcat 의 Connector 가 Connection 을 생성하면서 요청된 작업을 Thread 와 연결합니다. 기본 값은 8192 입니다.
accpetCount
Max-Connections 가 다 찼더라도 요청을 받기 위해 사용하는 대기열의 크기입니다. 만약 이 대기열까지 다 차게 되면 요청이 거절될 수 있습니다. 기본 값은 100 입니다.
maxThreads
톰캣 내 쓰레드 풀의 최대 개수입니다. 기본 값은 200 입니다. 또한 min 값도 따로 설정할 수 있는데 기본 값은 10 입니다. 따라서 thread 의 개수는 min ~ max 값입니다.
스레드 풀 min, max 값을 설정할 때는 당연히 적정 스레드 개수를 파악해서 설정해야 합니다. min 값이 지나치게 크면 유휴 스레드가 생기며, max 값이 너무 작으면 동시 처리 요청수가 줄어들겠죠. 또한 Tomcat 은 Non-Blocking IO 방식으로 여러 connection 이 1개의 thread 와 연결될 수 있습니다. accept-count 크기도 적절하게 유지되어야 하는데, 대기열이 커지면 메모리 문제가 발생하고, 대기열이 너무 작으면 들어오는 요청이 대부분 거절될 수 있기 때문입니다.
Ref
- 혼자 공부하는 컴퓨터 구조 + 운영체제 (강민철, 한빛미디어) (책입니다.)
- CPU 스레드 & 소프트웨어 스레드
- 완전히 정복하는 프로세스 vs 스레드 개념
- 스레드 모델, 사용
- [Java] 스레드 풀이란?



댓글남기기