해시맵 내부 동작 파헤쳐보기
Map
map 은 Key, value 쌍을 가지는 자료형이다. 중복 Key를 허용하지 않으며(한 Key당 최대 한 개의 Value), Value는 중복될 수 있다. Collection의 하위 타입이 아니기 때문에 리스트나 배열처럼 순차적인 연산이 되지 않는다. 주요 메서드는 다음과 같다.
boolean containsKey(Object key); //있는지 확인
V get(Object key); //가져오기
V put(K key, V value); //저장
Set<K> keySet(); //key 들을 Set 으로 추출
Collection<V> values(); //value 를 collection 으로 추출
Set<Map.Entry<K, V>> entrySet(); //key,value 쌍을 추출
여기서 특이한 점은 순회하는 방법이 keySet, values, entrySet 등 여러 개가 있다는 건데, 이는 자바가 모호성을 최대한 제거하려한 흔적이다. 단순히 map 자체를 순회한다고 하면 key 집합에 대한 순회인지 values 에 대한 순회인지 모호하기 때문이다. 따라서 저렇게 3개로 나뉜 메서드가 존재한다.
정렬
Map 의 정렬/순서 보장 여부는 구현체마다 다르다.
HashMap: 순서 없음.LinkedHashMap: 삽입 순서 유지 → LRU 캐시 구현에 유용TreeMap: Key의 Comparator 로 정렬(이진 검색 트리/레드-블랙 트리 기반)
동등성과 계약
대부분 구현체에서 Key 동일성은 equals()로 판단된다. 해시 기반은 hashCode도 중요하다. 당연히 equals가 같으면 반드시 hashCode도 같아야 한다. 잘못 구현하면 조회/중복 처리에서 오작동이 발생한다. IdentityHashMap만 예외적으로 ==(참조 동일성)로 비교한다.
Map 의 동시성
기본 구현체는 스레드 안전하지 않다. 따라서 필요시 Collections.synchronizedMap으로 감싸거나 ConcurrentHashMap 사용해야 한다.
HashMap
HashMap은 Map 인터페이스를 구현하고 있는 대표적인 클래스다. HashMap 의 key 는 해시값이 계산되어 있기 때문에 검색, 삽입에서 모두 O(1) 의 시간복잡도를 가진 효율적인 자료 구조이다.
HashMap 동작
해시는 데이터를 내부적으로 아래와 같은 bucket 배열에 Node 를 저장한다. 기본 크기는 16 이다.
transient Node<K,V>[] table;
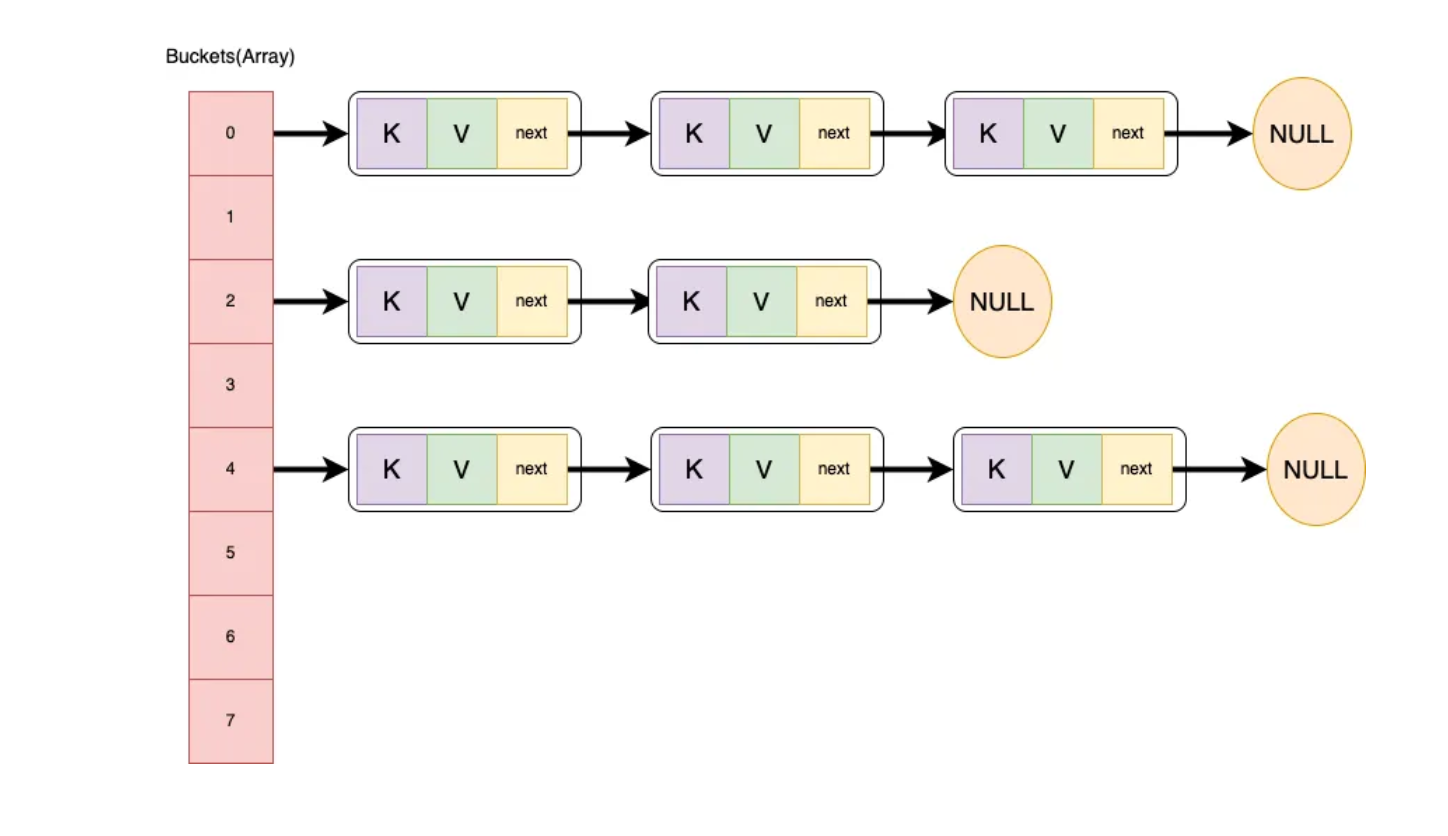
처음 생성할 때 보통 new HashMap<>() 으로 생성하는데 이렇게 되면 loadFactor 가 default (0.75f) 로 생성된다.
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
그리고 table 은 put 이 처음 호출될 때 초기화된다.
용어
- capacity: 버킷 배열 길이(항상 2의 거듭제곱).
- load factor(기본 0.75): 얼마나 차면 늘릴지 결정하는 비율.
- threshold = capacity × loadFactor:
size가 이 값을 넘으면 리사이즈.
put() 동작 흐름
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 1
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 2
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 3
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 4
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//5
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//6
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//7
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
table 이 null 이면 table 을 resizing 한다.
(n - 1) & hash결과가 table 에 없으면 새 노드를 넣고 종료한다. (capacity가 2의 거듭제곱이므로%대신 AND)hash 값이 겹치고 key 값이 동등하다면 값만 교체한다. 나중에 값 교체를 위해
e에 기존 노드를 기억한다.버킷이 레드-블랙 트리인 경우 트리 로직으로 삽입/검색을 한다. 결과가 기존 노드면 e에 그 노드를, 새 삽입이면 e=null 을 반환한다.
겹치는 값이 TreeNode 가 아니라면 뒤에 연결한다.
binCount >= TREEIFY_THRESHOLD - 1에서-1인 이유는 루프가 다음 노드(e)를 기준으로 세기 때문(헤드 제외 7회 이상 만났다면, 새 노드까지 합쳐 8개)
앞 단계(3/4/5)에서 동일 키의 노드
e를 찾았을 때의 동작이다.- 일반
put에선onlyIfAbsent=false이므로 무조건 값 교체가 발생한다. putIfAbsent경로였다면onlyIfAbsent=true→ 기존 값이null일 때만 교체한다.
- 일반
삽입 후
size가threshold를 넘으면 리사이즈(2배 확장)
충돌 처리: 체이닝(LinkedList) → 트리화(Red-Black Tree)
서로 다른 key 인데도 hash key 가 같을 수도 있다. 이런 상황을 **충돌(collision)**이라고 한다. 기본적으로 충돌 시에는 체이닝을 통해 해결한다. 하지만 JDK 8부터 버킷별 연결 리스트가 길어지면 성능 악화를 막기 위해 레드-블랙 트리로 전환한다.
- TREEIFY_THRESHOLD = 8 이상이면 트리화 후보
- 단, MIN_TREEIFY_CAPACITY = 64 미만이면 리사이즈를 먼저 시도(버킷 수를 늘려 충돌 자체를 줄이는 게 우선)
- 트리 길이가 다시 줄면 UNTREEIFY_THRESHOLD = 6 이하면 리스트로 되돌리기도 함
이로써 평균 시간복잡도는 **O(1)**이고 최악(많은 충돌)에서도 트리화 시 **O(log N)**이 보장된다.
리사이즈 전략
기본적으로 size > threshold(capacity×loadFactor)가 되면 capacity를 2배로 확장한다. 이때 엔트리들은 재배치가 될까? 아니면 그대로 있을까? 해시 위치를 (n-1) & hash 로 계산하기 때문에 재배치가 되어야 할 것만 같다.
하지만 기존 엔트리들이 전부 다시 해싱되지는 않는다. 핵심은 인덱스 계산식이 index = (n - 1) & hash라는 점이다. n 을 2배로 늘리면 마스크 비트가 하나 늘어나고, 그 새 비트(= oldCap)가 0인지 1인지에 따라 위치가 결정된다.
- 기존 용량:
oldCap = n - 새 용량:
newCap = 2n - 기존 인덱스:
oldIdx = (n - 1) & hash - 새 인덱스:
newIdx = (2n - 1) & hash
여기서 비트 성질상,
hash & oldCap== 0 → 그대로oldIdx에 남음hash & oldCap!= 0 →oldIdx + oldCap로 이동
즉, 각 버킷은 “low(그대로)”와 “high(+oldCap)” 두 갈래로만 갈린다. 해시를 다시 계산하지 않고, 저장해 둔 hash 필드의 한 비트만 확인해 빠르게 분배한다.
Node<K,V> loHead=null, loTail=null;
Node<K,V> hiHead=null, hiTail=null;
for (Node<K,V> e = oldTab[j]; e != null; e = next) {
next = e.next;
if ((e.hash & oldCap) == 0) { // 새 비트가 0 → low 리스트
if (loTail == null) loHead = e; else loTail.next = e;
loTail = e;
} else { // 새 비트가 1 → high 리스트
if (hiTail == null) hiHead = e; else hiTail.next = e;
hiTail = e;
}
}
tab[j] = loHead;
tab[j + oldCap] = hiHead;
이렇게 하면 풀 리해싱가 불필요하고 체이닝된 건 포인터 재연결만 하면 되니까 빠르게 해결된다.
vs hashTable
HashTable 은 HashMap 이전에 사용되던 비슷한 동작의 자료형이다. 하지만 synchronized 로 인한 성능 저하로 더 이상 사용하지 않는다.
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
Hashtable은 synchronized 키워드를 사용해 스레드 안전하게 만들었다. 하지만 이는 장점이자 단점인데, 멀티스레드 환경이 아니라면 Hashtable은 HashMap 보다 성능이 떨어진다. 또한 HashMap 은 보조해시를 사용하기 때문에 보조 해시 함수를 사용하지 않는 Hashtable 에 비하여 해시 충돌이 덜 발생할 수 있어 상대적으로 성능상 이점이 있다.
그렇다면 스레드 안전하면서 성능도 좋은 해시맵은 없을까?
ConcurrentHashMap
내가 좋아하는 ConcurrentHashMap 이다. ConcurrentHashMap 은 Hashtable 클래스의 단점을 보완하면서 멀티스레드 환경에서 사용할 수 있도록 나온 클래스다. 나는 샘플 프로젝트와 같은 곳에서 저장이 필요할 때, 굳이 데이터베이스를 쓰지 않고 튼튼한 ConcurrentHashMap 을 사용하기도 한다.
ConcurrentHashMap 은 읽기 작업에는 여러 쓰레드가 동시에 읽을 수 있지만, 쓰기 작업에는 특정 세그먼트 or 버킷에 대한 Lock을 사용한다.
Put
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
//1
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
//2
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//3
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
//4
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
//5
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
//6
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
//7
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//8
addCount(1L, binCount);
return null;
}
무한 루프(재시도 루프)
- 경쟁/리사이즈로 테이블 상태가 바뀔 수 있어 for(;😉 로 반복한다.
테이블 초기화
- 전역 잠금 없이 sizeCtl를 이용한 CAS 기반으로 초기화
빈 버킷이면 CAS로 삽입 (락 없음)
tabAt/casTabAt은Unsafe를 통한 volatile 읽기 + CAS 쓰기.성공 시 락 없이 바로 종료한다.
리사이즈 진행 중 감지 & helpTransfer
버킷 헤드의
hash가MOVED(특수 값)면 ForwardingNode 로 리사이즈 중이다.현재 스레드가 helpTransfer로 분할 복사를 돕고, 새 테이블을 기준으로 루프를 재시작한다.
onlyIfAbsent 빠른 경로(락 없이 첫 노드 확인)
putIfAbsent시, 첫 노드가 같은 키고 값이 이미 있으면 락 없이 즉시 반환(업데이트 생략)한다.
버킷 단위 잠금으로 삽입/업데이트
잠금 범위는 버킷(head 노드) 단위로 전역 락이 없어서 높은 동시성을 가진다.
리스트면 순회해서 동일 키를 업데이트하거나 리스트 끝에 추가하낟.
트리면
TreeBin.putTreeVal사용한다.(내부는 레드-블랙 트리 + 자체 락)
트리화 판단 & 반환 분기
- 체인 길이가 임계(기본 8) 이상이면 트리화를 시도하고 테이블이 작으면 우선 체이닝을 한다.
카운터 증가 & 필요 시 리사이즈 트리거
카운터 셀(Stripped counters) 로 size를 근사/합산, 임계 초과면 transfer 을 트리거
새 삽입이면
null반환, 기존 키 업데이트면 위에서oldVal반환
CAS 란?
CAS(Compare-And-Swap)는 ""현재 값이 내가 기대한 값이면 새 값으로 바꾼다"를 단 한 번에(atomically) 수행하는 하드웨어 수준의 연산이다. 락을 잡지 않고도 여러 스레드가 경쟁 없이(정확히는 블로킹 없이) 공유 데이터를 갱신할 수 있게 해주는 락-프리(lock-free) 알고리즘의 기본 빌딩블록이다.
동작 개념
boolean CAS(addr, expected, newVal):
atomically do:
if *addr == expected:
*addr = newVal
return true
else:
return false
- 성공: 메모리의 현재 값이
expected와 같아 교체됨 →true - 실패: 누군가가 이미 바꿔서 현재 값이 달라짐 → 아무 것도 안 하고
false
사용하는 이유
- 무잠금 삽입/갱신: 빈 칸에 첫 노드를 넣을 때
null → newNode를 CAS 한 번으로 끝낼 수 있다. (예:ConcurrentHashMap.casTabAt(...)) - 낮은 대기 시간: 락 대기(block) 대신 짧게 재시도하는 스핀 루프로 처리
- 확장성: 고경쟁 구간을 잘게 쪼개서(버킷 단위 등) 멀티코어 활용 극대화
Java 예시
AtomicInteger ai = new AtomicInteger(0);
int prev;
do {
prev = ai.get(); // 기대값 읽기
} while (!ai.compareAndSet(prev, prev + 1)); // 실패 시 재시도
ConcurrentHashMap도 빈 버킷엔 CAS, 이미 차 있으면 버킷 헤드만 동기화하는 하이브리드 전략을 사용한다.
메모리 가시성(자바 메모리 모델)
Atomic*의compareAndSet은 원자성 + 가시성을 보장한다. 성공한 CAS는 사실상 volatile 읽기/쓰기의 효과가 있어, 다른 스레드에서 즉시 관찰된다. JDK 9+의VarHandle도compareAndSet,weakCompareAndSet*등으로 비슷하게 보장한다.
장단점
장점
- 락 오버헤드/컨텍스트 스위치 없음 → 낮은 지연, 높은 처리량
- 데드락, 우선순위 역전 같은 락 특유의 문제 회피
단점
- 경쟁이 심하면 실패→재시도 루프가 길어져 CPU 낭비(스핀) 가능
- 공정성 없음: 운 나쁜 스레드가 계속 지는 스타베이션 가능
- ABA 문제: 값이 A→B→A로 돌아오면 “안 바뀌었다”고 착각할 수 있음 → 해결: 버전 태그를 함께 비교(예:
AtomicStampedReference,AtomicMarkableReference)